This is a brief summary of paper for me to study and organize it, Siamese Recurrent Architectures for Learning Sentence Similarity (Mueller and Thyagarajan., AAAI 2016) I read and studied.
Thes propose a siamese neural network based on LSTM to compare a pair of sentences.
First, they encode two sentence of different length into fixed-size vectors using an LSTM as follows:
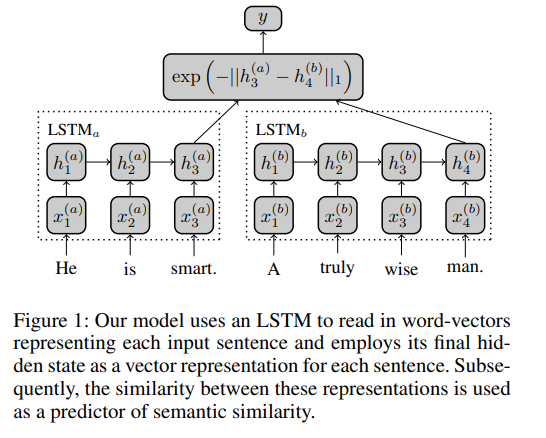
As you can see, they used Manhattan distance as objective function.
In their paper, they use data augmentation for NLP(natural language processing) called synonym augmentation.
synonym augmentation replace random words with one of their synonyms, for example, using Wordnet.
If you want to know the property of simamese network, refer to the lecture below:
Siamese network on face recognition
</div>
Note(Abstract):
They present a siamese adaptation of the Long Short-Term Memory (LSTM) network for labeled data comprised of pairs of variable-length sequences. Their model is applied to assess semantic similarity between sentences, where we exceed state of the art, outperforming carefully handcrafted features and recently proposed neural network systems of greater complexity. For these applications, They provide wordembedding vectors supplemented with synonymic information to the LSTMs, which use a fixed size vector to encode the underlying meaning expressed in a sentence (irrespective of the particular wording/syntax). By restricting subsequent operations to rely on a simple Manhattan metric, we compel the sentence representations learned by our model to form a highly structured space whose geometry reflects complex semantic relationships.
Download URL:
The paper: Siamese Recurrent Architectures for Learning Sentence Similarity (Mueller and Thyagarajan., AAAI 2016)
The paper: Siamese Recurrent Architectures for Learning Sentence Similarity (Mueller and Thyagarajan., AAAI 2016)
Reference
- Paper
- How to use html for alert