This is a brief summary of paper for me to note it, Sequence to Sequence Learning with Neural Networks (Sutskever et al., NIPS 2014)
Their architecture is end-to-end neural network with two LSTM(one for input sequence, another for output sequence).
The goal of the LSTM is to estimate the conditional probability \(p(y_1, . . . , y_{T′}| x_1, . . . , x_T)\) where \((x_1, . . . , x_T )\) is an input sequence and \(y_1, . . . , y_{T′}\) is its corresponding output sequence whose length \(T′\) may differ from \(T\). The LSTM computes this conditional probability by first obtaining the fixeddimensional representation \(v\) of the input sequence \((x_1, . . . , x_T )\) given by the last hidden state of the LSTM, and then computing the probability of \(y_1, . . . , y_{T′}\) with a standard LSTM-LM formulation whose initial hidden state is set to the representation \(v\) of \(x_1, . . . , x_T\)
\[p(y_1,...,y_{T'}|x_1,...,x_T) = \prod_{t=1}^{T'} p(y_t+v, y_1,...,y_{t-1})\]In this equation, each \(p(y_t|v, y_1, . . . , y_{t−1})\) distribution is represented with a softmax over all the words in the vocabulary. Note that we require that each sentence ends with a special end-of-sentence symbol “
The one below is simple illustration of their architecture.
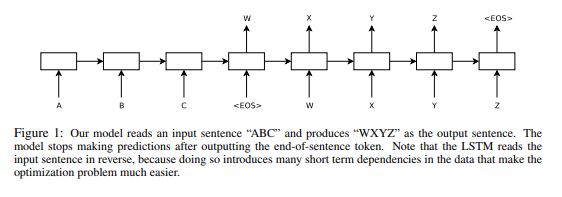
This paper for translation task in NLP field propose three key points.
- How to deal with sequence data like text which has a variable length sequence in both input and output with two LSTMs(i.e. one is encoder, the other is decorder)
- They use a reversed input(source sequence) to tackle long range temporal dependencies but target sequences are not reversed.
- They use left-to-right beam search(i.e. beam size of 1, 2, or 12) in decoder for the better target sequences which is maaintains a small number B of partial hypotheses.
They implemente their model on the WMT’14 English to French translation task.
For train and test time, they were able to do well on long sentences because they reversed the order of words in the source sentence but not the target sentences in the training and test set.
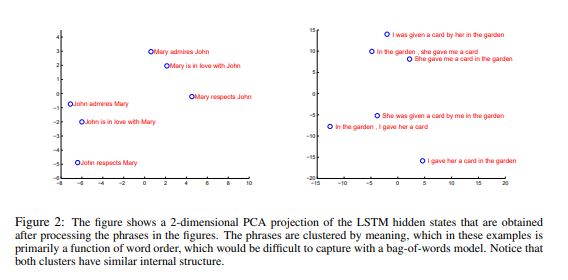
As you can see below, the representation shows that the representations are sensitive to the order of words, while being fairly insensitive to the replacement of an active voice with a pssive voice.
The paper: Sequence to Sequence Learning with Neural Networks (Sutskever et al., NIPS 2014)