This is a brief summary of paper, Attentive Language Models (Salton et al., IJCNLP 2017).
The reason I summarize the paper is to study attention mechanism and arrange the paper I read.
The concept of this paper is attention mechanism in a memory buffer on language model of NLP task.
The recurrent neural network has improved the state-of-the-art in language model.
There is problem as follows
RNN-LMs sequentially propagate forward a context vector by integrating the information generated by each prediction step into the context used for the next prediction.
Oen consequence of this forward propagation of information is that older information tend to fade frome the context as new infromation is integrated into the context.
As a result, RNN-LMs struggle in situations where there is a long-distance dependecy because the relevant information from the start of the dependency has fasded by the itme the mode has spanned the dependency.
A second problem is that the context can be dominated by the more recent information so when an RNN-LM does make an error r this error can be propagated forward resulting in a cascade of errors through the rest of the sequence.
They utilizse “attention” which is developed in recent sequence-to-sequence research like Neural Machine Translation.
They think of the attention mechanism as way the model could bring forward context information from different points in the context sequence histroy.
Thus, they hypothesiz that the attention mechanism enalbes RNN-LMs as follows:
a) birdge long-distance dependenies, thereby avoding erorrs
b) to overlook recent errors by choosing to focus on contextual information preceding the error, thereby avoding error propagtaion
Language model models the probability fo a sequence of words by modeling the joint probability of the words in the sequence using the chain rule:
\[p(w_1, ... , w_N) = \prod_{t=1}^{N}p(w_n | w_1, ... , w_{n-1})\]where N is the number of words in the sequence.
They employ a multi-layered RNN to encode the input and, at each timestep, they store the output of the last recurrent layer (i.e., its hidden state \(h_t\)) into a memory buffer. We compute a score for each hidden state \(h_i\) (\(\forall\) i ∈ {1, . . . , t − 1}) stored in memory and use these scores to weight each \(h_i\). From these weighted hidden states we generate a context vector \(c_t\) that is concatenated with the current hidden state \(h_t\) to predict the next word in the sequence. The following illustrates a step of our model when predicting the fourth word in a sequence.
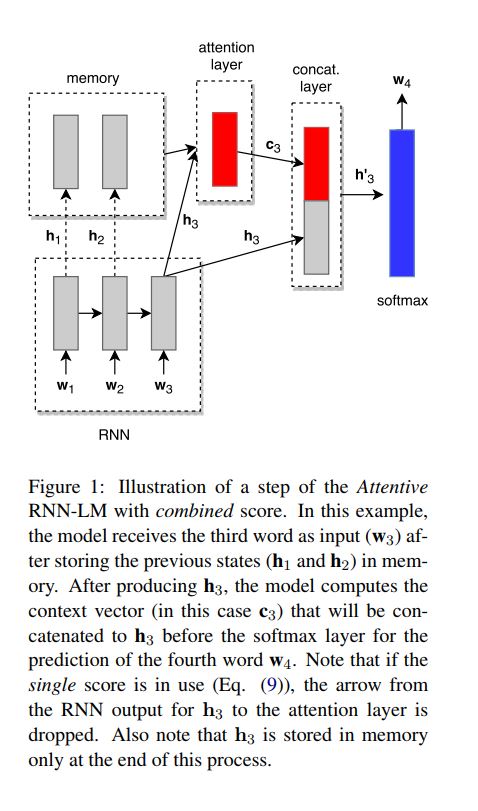
Also they proposed two different attention score funtions that can be used to compute the context vector \(c_t\).
One calculates the attention score of each \(h_i\) using just the information in the state(the single(\(h_i\)) score).
The other calculates the attention scores for each \(h_i\) by combining the information from that state with the information from the current state \(h_t\)(the conmbined(\(h_i,h_t\)).
Let’s see the formal way to calcualte each \(h_i\).
where \(x_t\) is the input at timestep t:
\[h_t = RNN(x_t, h_{t-1})\]The context vector \(c_t\) is then generated as follows:
\[c_t = \sum_{i=1}^{t-1}a_ih_i\] \[score(h_i, h_t) = \begin{Bmatrix} single(h_i) \\ combined(h_i, h_t) \\ \end{Bmatrix}\]They then concatenate \(c_t\) with the current state \(h_t\) using a concatenation layer, where \(W_c\) is a matrix of parameters and \(b_t\) is a bias vector.
\[h_t^{'}=tanh(W_c[h_t;c_t]+b_t)\] \[p(w_t|w_{<t},x) = softmax(Wh_t^{'}+b)\]Let’s see the single anc combined score :
\[single(h_i) = v_s\bullet tanh(W_sh_i)\]where the parameter matrix \(W_s\) and vector \(v_s\) are both learned by the attention mechanism and \(\bullet\) represent the dot product.
\[combined(h_i,h_t) = v_s\bullet tanh(W_sh_i+W_qh_t)\]where the parameter matrices \(W_s\) and \(W_q\) and vector \(v_s\) are learned by the attention mechanism, and \(\bullet\) is also dot product.
Reference
- Paper
- How to use html for alert
- How to use MathJax
- For your information
- Attention? Attention! on Lil’Log blog
- Self-Attention Mechanisms in Natural Language Prcessing on Alibabacloud
- Deep Learning for NLP Best Practices on ruder blog
- Soft & Hard Attention on Jonathan Hui Blog
- Attention Mechanism on Heuritech
- A Brief Overview of Attention Mechanism on Medium
- Attention and Memory in Deep Learning and NLP on WILDML
- Kor ver
- Slide