This is a brief summary of paper for me to study and organize it, Universal Language Model Fine-tuning for Text Classification (Howard and Ruder., ACL 2018) I read and studied.
They propose how to fine-tune Language model to transfer into another task.
The fine-tuning of LM has a problem called catastrophic forgetting
So They argue, when you fine-tune LM, you apply correct way to do fine-tunning.
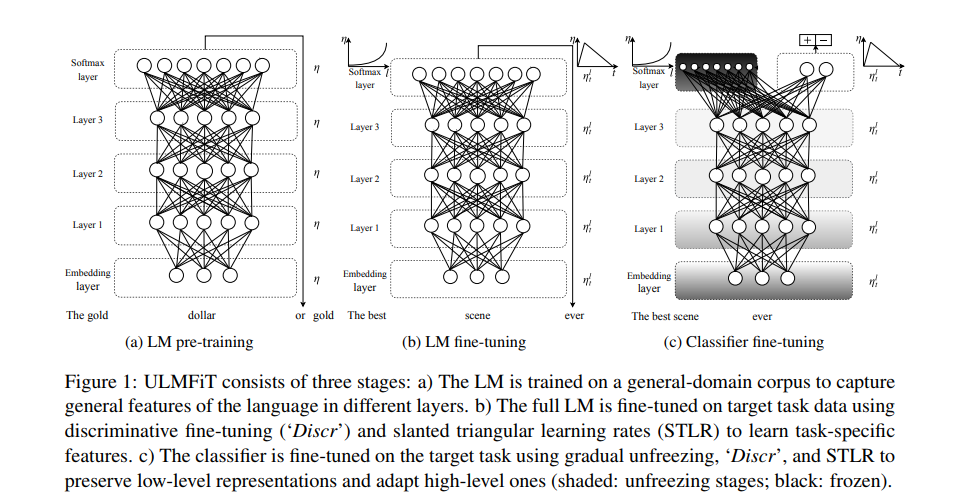
They propose two types of fine-tuning, discriminative fine-tuning and slanted triangular learning rates.
- Discriminative fine-tuning
As different layers acpture different types of information(Yosinki et al., 2014), they shoud be fine-tuned to different extents using different learning rates.
- slanted triangular le fine-tuning
This is the way to adapt model’s parameters to task-specific features to quickly converge to a suitable region of the parameter space in the beginning of training and the refine its parameter.
Also they proposed fine-tuning of classifier.
The way to fine-tune the classifier is gradual unfreezing which is unfreezing the the model starting from last layer as this contains the least gneenral knowledge. i.e. They first unfreeze the last layer and fine-tune all unfrozen layers for one epoch. They then unfreeze the next lower layer and repeat, until they fine-tune all layers until convergence at the last iteration.
The paper: Universal Language Model Fine-tuning for Text Classification (Howard and Ruder., ACL 2018)
Reference
- Paper
- How to use html for alert
- For your information