This pase is summary of my class of Advancee Topics in computer science about Security Field’s file similarity.
When you want to search for the same files, crytographic hash funciton is useful to find out that two file is the same one.
Let’s see what the cryptographic hash function is on wikipedia.
A crytographic has function is a special of hash function that has certain properties which make it suitable for use in cryptography. It is a mathematical algorithm that maps data of arbitrary size to a fixed size(a hash) and is designed to be a one-way function, that is, a function which is infeasible to invert.
To sum up, one-way function is the only way to recreate the input data from an ideal cryptographic hash function’s output is computationally impossible with brute-force search.
Because of the following main properties of cryptographic hash function :
-
it is deterministic so tha same message always results in the same hash
-
it is quick to comput the hash value for any given message
-
it is infeasible to generate a message from it hash value except by trying all possible messages(computationally impossible).
-
a small change to a message should change the hash value so extensively that the new hash value appears uncorrelated with the old hash value.
-
it is infeasible to fine two different messages with the same hash value.
In Cryptography, The input data is often called the message, and the output(hash value or hash) is often called the message digest, simply the digest, or chipher text.
Because of the main feature of cryptographic hash function, when you find out the same two file, it is usefule to use cryptographic hash function.
utiliziing the crytographic hash function is efficient than when you don’t use hash function to compare two files. That is because hash is a fixed size less than the original input message.
If you want to find out two files, consider cryptographic hash function like sha-256 and MD5.
Where you wnat to find out similar two files is difficult to use cryptographic hash function.
Let’s say with the following examples.
FILE A : The Jaccard index, also known as Intersection over Union and the Jaccard similarity coefficient (originally coined coefficient de communauté by Paul Jaccard), is a statistic used for comparing the similarity and diversity of sample sets. The Jaccard coefficient measures similarity between finite sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets…
FILE B : The Jaccard index, also known as the Jaccard similarity coefficient (originally coined coefficient de communauté by Paul Jaccard), is a statistic used for comparing the similarity and diversity of sample sets. The Jaccard coefficient measures similarity between finite sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets…
The two documents above is similar but not the same ones, if you use cryptographic hash function to compare two files above, the hashs is totally different, just because of text like Intersection over Union and.
The reason the two hash value is different is for feature of cryptographic hash function which a small change to message make change to the hash a lot.
so as to find similar files, use Jaccard Index
Jacaard Index
Let’s see the definition of Jaccard Indes on wikipeidia
The Jaccard index, also known as Intersection over Union(IOU) and the Jaccard similarity coefficient is a statistics used for comparing the similarity and diversity of sample sets.
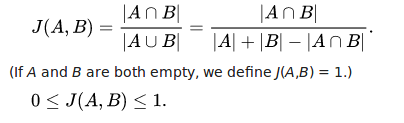
As you can see above,
If A = B J(A, B) = 1, Exactly same!
If the intersection between A and B is zero, J(A, B) = 0. exactly different.
** the set mean there is no duplicate in a set. **
Distance vs Similarity
Distance is a metric for similarity,
In the clustering, if the distance between two points is far, the two point is different.
But if they are located near, The two point is similar.
So we can define like this:
Distance(A, B) = 1 - Similarity(A, B)
e.g. let’s see Distance exmpale like Hamming distance
The Hamming distance between the follwoings is 2
| 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
As you can see above, The different thing is 2(Hamming distance).
except for hamming distance, there is Levenshtein distance
How to covert a file to A(a mass)?
If you have FileA like this :
- FileA : “The Jaccard index also known as Intersection….”
If you use n-gram, let’s see 3-gram
A = {“The Jaccard index”, “Jaccard index also”, “index also known”…….}
word-based VS byte-based
on 3-gram
-
Word-based : A = {“The Jaccard index”, “Jaccard index also”, “index also known”…….}
-
byte-based : A = {“The”, “he “, “e J”, “ Ja”, “Jac”, ……..}
set-based VS bag-based
Let’s say FileA = “aaaaa”.
on 3-gram
-
set-based = {“aaa”} not including duplicate
-
bag-based = {“aaa”, “aaa”, “aaa”} including duplicate
For convenience, You can use hash function on the A above.
To sum up of Jaccard,
For simplicity, Let’s see integer sets
A = {1,2,3,4,5} B = {2,3,4,5,6,7}
J(A,B) = 4/7
-
The union of A and B : {1,2,3,4,5,6,7}
-
The intersection of A an B : {2,3,4,5}
But in the method of Jaccard Index, There is problems.
-
set opeartion is expensive in terms of computational resources. What if file size is quite large?
- Solution > Broder’s theorem


-
A huge number fo files cause a large number of pair-wise comparison among files O(n^2)
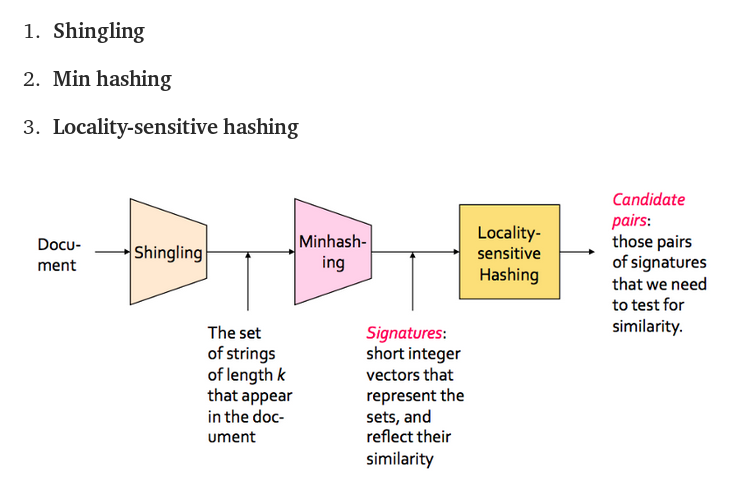
- simhash, Locality sensitive hashing