This paper,Bidirectional LSTM-CRF Models for Sequence Tagging (Huang et al., arXiv 2015), refered to how to use BiLSTM+CRF for seqeunce tagging in NLT task.
Normally, If you run into Sequence tagging problem, you would think of RNN.
It is because the key point is seqeunce in the problem.
So This paper implemented LSTM network, BiLSTM network, LSTM-CRF Network, BiLSTM-CRF network.
First, A LSTM network deals with information from left to right :
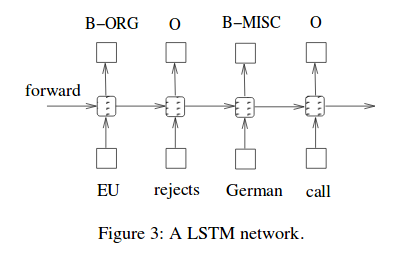
as you can already know and understand RNN structure, the utilize the infromation of previous information and current input.
So LSTM utilize the past information at the time, But BiLSTM is different as follows:
Second, Bidirectional LSTM network is like this :
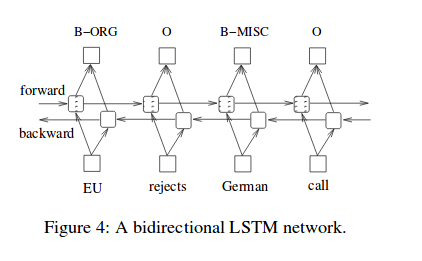
BiLSTM have two type of LSTM, one is forward LSTM and the other is backward LSTM.
operation of the two LSTM is the same, the direction of information flow is different.
Let’s see how to take advantage of BiLSTM to extract information.
there two ways to extract information. one is only final state, the other is sequence output at the time.
firstly, use final state(output) that it summarize the infromation of forward and backward respectively :
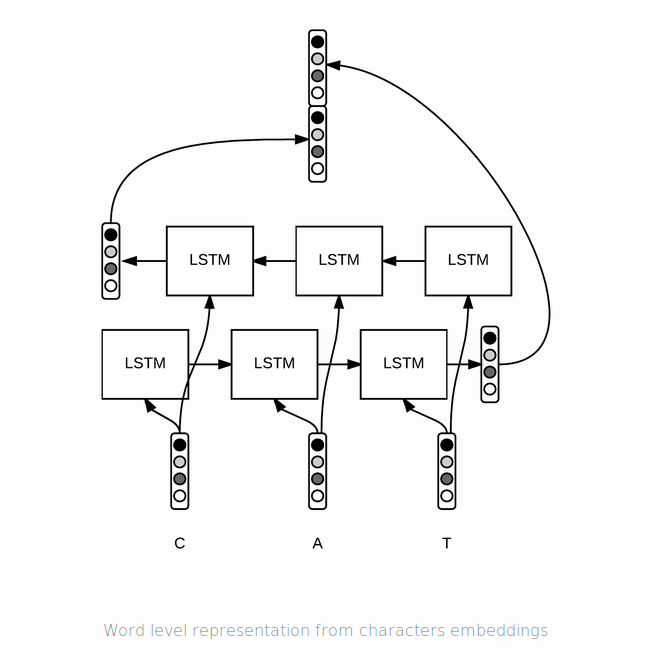
OR
Seconde, methods to use contextual represetation of forward and backward respectively.
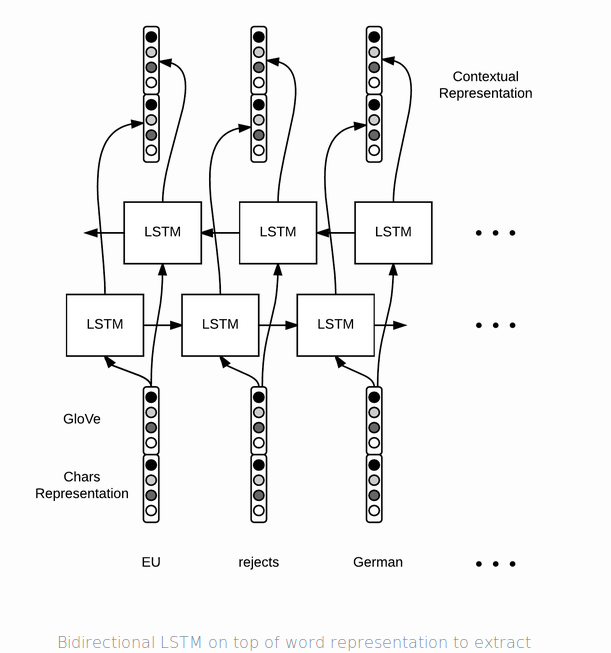
as you could know, for sequence labeling problem, we need to use contextual represenation.
conditional random field
Conditional random field(CRF) is useful graphical model on probability.
It consider sentence level tag sequence information.
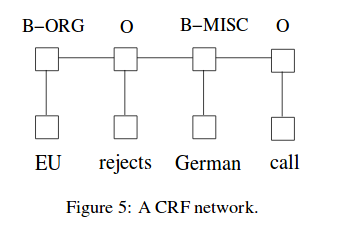
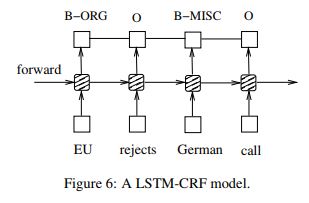
Let’s see the combination of LSTM and CRF
First, LSTM with a CRF layer
Second, Bi-direcational LSTM with A CRF Layer
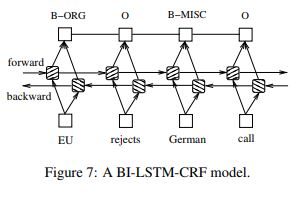
As you can know, in this paper, LSTM is variant like Peephole LSTM.
They use cell state as input for input, output, forget gate.
In particular, the weight matrix from cell to gate vectors are diagonal.
additionaly, they used BIO2 annotation standard for Chunking and NER tasks.
also they use the connection trick of features like this:
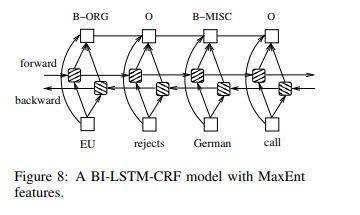
They estimated the robustness of models with respect to engineered features(spelling and context features).
So they trained their models with word features only(spelling and context features removed).
they argued that
-
CRF model heavily rely on engineered features to obtain good performance.
-
on the other hand, LSTM, BiLSTM, and BiLSTM-CRF models are more robust and they are less affected by the removal of engineering features.
There used the spelling features and context features
- spelling features :
• whether start with a capital letter
• whether has all capital letters
• whether has all lower case letters
• whether has non initial capital letters
• whether mix with letters and digits
• whether has punctuation
• letter prefixes and suffixes (with window size of 2 to 5)
• whether has apostrophe end (’s)
• letters only, for example, I. B. M. to IBM
• non-letters only, for example, A. T. &T. to ..&
• word pattern feature, with capital letters, lower case letters, and digits mapped to ‘A’, ‘a’ and ‘0’ respectively, for example, D56y-3 to A00a-0
• word pattern summarization feature, similar to word pattern feature but with consecutive identical characters removed. For example, D56y-3 to A0a-0
- context features : uni-gram, bi-gram or tri-gram
The paper: Bidirectional LSTM-CRF Models for Sequence Tagging (Huang et al., arXiv 2015)
Reference
- Paper
- How to use html for alert
- blogs related to information of Linear-chain CRF
- Guillaume Genthial blog’s Sequence Tagging with Tensorflow
- WILDML’s RNN
- aymericdamien’s RNN
- Implementing a linear-chain Conditional Random Field (CRF) in PyTorch on towardsdatascience
- HMM, MEMM, and CRF: A Comparative Analysis of Statistical Modeling Methods on llibabacloud
- Maximum Entropy Markov Models and Logistic Regression on David S. Batista blog
- Introduction to Conditional Random Fields on Edwin Chen blog
- Conditional Random Field Tutorial in PyTorch on Towards Data Science