Overall, This paper,Efficient Estimation of Word Representations in Vector Space (Mikolov et al., arXiv 2013), is saying about comparing computational time with each other model, and extension of NNLM which turns into two step. one is training word vector and then the other step is using the trained vector on The NNLM.
In estimaiting continuous representations of words including the well-known Latent Semantic Analysis(LSA) and Latent Dirichlet Allocation(LDA).
They are saying the neural network is performing better thatnn LSA for preserving linear regularities among words. even LDA becomes computationally very expensive on large data sets.
In this paper, the computational time complexity is defined as follows:
The training complexity is proportional to :
O = E * T * Q
Where E is number of the training epochs, T is the number of the words in the training set and Q is defined further for each model architecture.
They are saygint when you compute computational time, it heavily depens on the number of output units or hidden layer units.
The best expensive one of two units is first output units, after that, the second one is hidden layer.
So They implemented hiararchical softmax with huffman tree to reduce output unit. but the bottleneck situation remains in hidden layer.
Finally they got rid of the hidden layer, so their model heavily depends on the efficiency of the softmax normalizations.
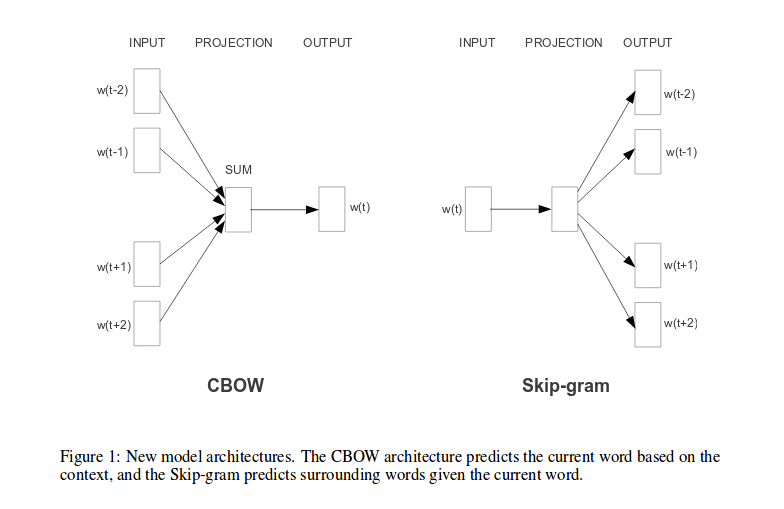
The models are called CBOW(continuous bag of word) and skip gram.
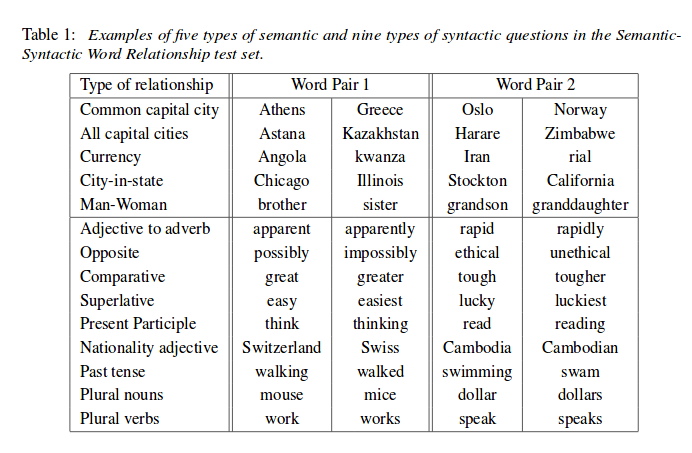
Let’s see an examle they used for testing syntactic and semantic questions.
Some of the resulting word vectors were made available for future research and comparison :
- Senna
- Metaoptimize-wordreprs
- RNNLM
- AI stanford
Their idea to create new model for the continous represenation of words is from that neural network language model can successfully trained in two steps: first continuous word vectors are learned using simple model, and then the N-gram NNLM is trained on top of these distributed representations of words.
They introduced two model based on their ideas. those are called one is CBOW and The other is Skip gram.
CBOW : predicting a word with future and history words before and after a middle word, so The weight matrix between the input and the projection layer is shared for all word positions in the same way in the NNLM.
Skip gram : this model used each current words as an input to a log-linear classifier with continuous projections layer, and predict words within a certain range before and after the current word.
</br> If you want to download the data set, visit here
The paper: Efficient Estimation of Word Representations in Vector Space (Mikolov et al., arXiv 2013)
Reference
- Paper
- Quoar
- Reference
- How to use html for alert
- My github repository to translate the test set of semantic and syntactic into Korean test set