I think sentence embeddings, document embeddings, and pragraph embedding have been studied in NLP, Because word embedding have beend tired in NLP field.
Nowadays, it is important to embed sentences, documents, or paragraph on sentiment analysis and text classification.
So I read a paper about how to embed setences and documents.
The title of the paper is Distributed Representations of Sentences and Documentes (Le et al. arXiv 2014).
Let’s see the models they argue for paragraph vector. ahead of proceeding to the inpiration of their model.
The inspired model is to predict next word if you know some context. let’s say “the cat sat on ~” is a sentences to make word embeddings.
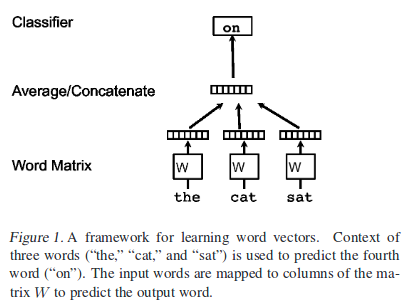
The framework above is learning word vectors. this task is to predict a word given the other words in a context.
The objective of the model above is to maximize the average of log probability.
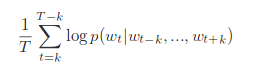
The prediction task is typically done via a multiclass classifier, such as softmax.
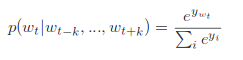
each yi in the fomulation above is unnormalized log-probability for each output word i, computed as
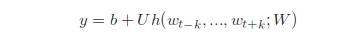
On image above, U,b are the softmax parameters. h is constructed by a concatenation or average of word vector extracted from W.
Let’s see the two models they argue for paragraph vector.
First is the Distributed Memory Model of Paragraph Vector(PV-DM).
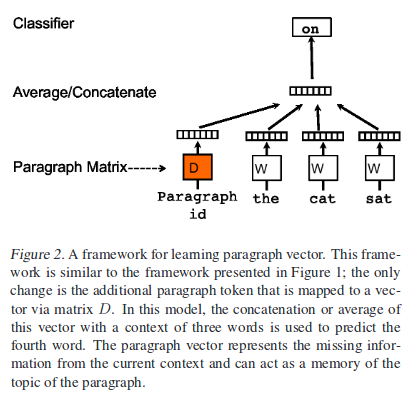
In the model above, The contexts are fixed-lenghth and sampled from a sliding window over the paragraph. The paragraph is shared across all contexts generated from the same paragraph but not across paragraph. The word vector matrix W, however, is shared across pargraphs. i.e. the vector for “powerful” is the same for all paragraph.
Second is the Distributed Bag of words(PV-DBOW).
This model is simple, This way is to ignore the context words in the input, But force the model to predict words randomly sampled from the paragraph in the output. i.e. paragraph vector is trained to predict the words in a small window.
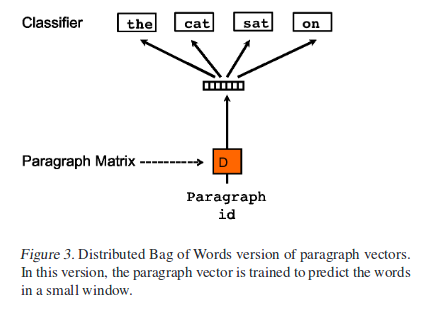
Keep in mind of how to learn the paragraph vector for new paragraph.
frankly speaking, If you have many documents, in all the documents, the same senteces is absolutely the fewest.
So when you test with test data. you have to fix the rest of vector representation except for paragraph vector on test time to learn pragraph vector.
If you want to know information about appilication of thie method, read another paper, titled Document Embedding with Paragraph Vectors (Dai et al. arXiv 2015)
They have proven How good their paragraph vector is at NLP task such sentiment analysis and informtional retrieval.
They have two ways you can embed setences, document or paragraph. So they propose Pragraph Vector, an unsupervised framework that learns continuous distributed vector representations for pieces of text. Two models is called PV-DM and PV-DBOW. PV-DM is The Distributed Memory Model of Paragraph Vector. PV-DBOW is the Distributed Bag of Words version of paragraph vector.
If you want to download the data set this paper used, visit the followings : Sentiment analysis from stanford universityThe paper: Distributed Representations of Sentences and Documents (Le et al. arXiv 2014)
Reference
- Paper
- How to use html for alert
- For your information
- Document Embedding with Paragraph Vectors. Dai et al. 2015 arXiv