After reading this paper,The Distributional Hypothesis (MagnusSahlgren., 2008), the discributional hypothesis mean you can estimate the meaning of word from distribution of words in context.
In here, context could be a sentence, paragraph or document and so forth. So when I find the meaning of word, the distribution of words help rather than usage of words.
Let’s see about it.
So, how the distribution of words in the text helps analysis of word meaning is two methods said in this paper.
One is Syntagmatic relation. The relations concern positioning, and relate entities that co-occur in the text like a sentence, paragraph and a document.
For example, The prime example of co-occurence events is collocations, such as “hermetically sealed”, where the first word, “hemetically”, very seldom occurs without the second word, “sealed”.
This means there is a pair of words often written together, this information helps you make vector of word simliar in semantics.
The other is Paradigmatic relations. These relations concern substiution, and relate entities that do not co-occur in the text; i.e. the neighbor of words in paradigmatic relations is the same but they cannot occur at the same time.
For example, like the words “hungry” and “thirsty” in the setence, “the man is [hungry|thirsty]”.
This information helps you make simliar vectors in semantics.
- What distributional hypothesis means is :
The refined distributional hypothesis : A distributional model accumulated from co-occurence information contains syntagmatic relations between words,
while a distributional model accumulated from information about shared neighbors contains paradigmatic relations between words.
Syntagmatic models
Syntagmatically related words can also be defined as words that co-occur within the same text region, like a sentence, paragraph, or a document.
Thus, There is at least one parameter that applies to syntagmatic models:
- The size of the context region within which co-occurences are counted.
In large contexts nearly every term can co-occur with every other; thus this must not mean anything for their semantic properties.
So, What would be a more linguistically justified definition of context in which to collect sytangmatic information? Perhaps a clause or a setence, since they seem to be linguistic univerals;
the smaller context like two words is very few, this means the majority of terms never co-occur.
Regardless of the use of documents, sentences, or phrases to harvest co-occurences, the implementational basis is the same.
Syntagmatic models collect text data in a words-by-documents co-occurence matrix in which the cells indicate the normalized frequency of occurence of a word in a document as followings:
Table 1 below show you how to collect text data by syntagmatic model. w1 has occured one time in document 2, while w2 has occured one time and document 3 and three times in document 6.
The point of this representation is that we can compare the row vector called context vector.
using linear algebra, so that words that have occured in the same documents will get high pair-wise similarity scores.

Paradigmatic model
Paradigmatically related words are words that do not themeselves co-occur, but whose surrounding words are often the same.
For example, in the case of between “bad news” and “good news”, it is “bad” or “good”.
The paradigmatic relations need not only consist of words that share the same immediately preceding or succeeding neighbor or neighbors. But you can also utilize the paradigmatic relation that may just as well be defined as words that share several of the nearnest preceding or succeeding neighbors.
Thus, there are at least three parameters that apply to paradigmatic models:
-
The size of the context region within which paradigmatic information is collected.
-
The position of the words within the context region.
-
The direction in which the context region is extended (preceding or succeeding neighbors)
the contex window is the number of preceding or succeeding neighbor like 1+1-size.
But if context size of preceding or succeeding neighbors could be differenct. it is like 1+2 size such as 1+0 1, where 0 means that the word is ignored.
For example,
-
a really splendid time -> splendid: (a 0) + (time)
-
a particularly wonderful time -> wonderful: (a 0) + (time)
To sum up, The implementationl details of paradigmatic models are the same regardless of our choice of context window;
paradigmatic models collect text data in a words-by-words co-occurence matrix that is populated by counting how many times words occur together within the context window.
Let’s see an example as folloings:
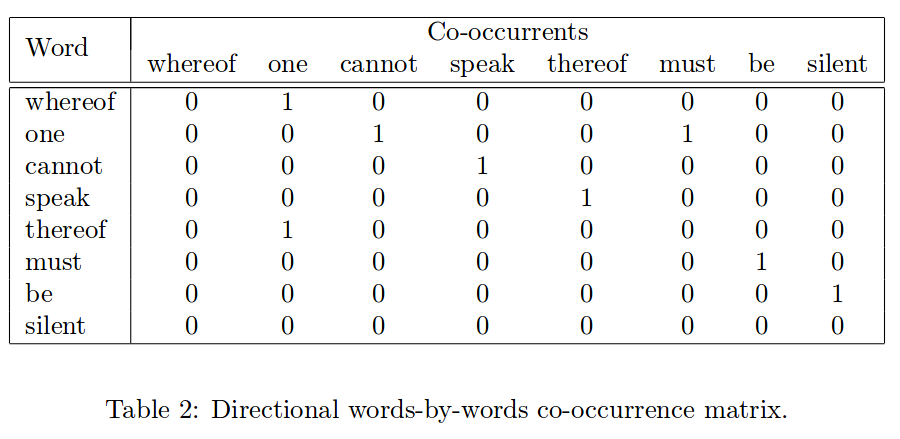
The words-by-words matrix above is called a directional co-occurence matrix, in the table 2 above, thr row vectors contain co-occurence counts with words that have occured one position to the right of the words, while the column vectors contain co-occurence counts with words that have occured one position to their left.
So table 2 allows you to compare the right and left contexts separately, In this time, you can use the rows vector and column vector for a words as a vector by concatenating.
Also you could symmetrically counts words that have occured one position both to the right and left, this mean you count to both directions within the context window.
Reference
- Paper
- material of lecture in stanford university
- How to use html for alert