How to get Text data of wikipedia
When you start to get in Deep Learning or Machine Learning, you must have data to train and test with your machin learning algorithm.
Basically, MNIST data or CIFAR-10 and so forth are given with Deap Learning and Machine learning framework like Tensorflow.
Even in tensorflow You easily get data of MNIST by calling some function like this.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
If you know how to get MNIST data with Tensorflow, refer to MNIST of Tensorflow or My blog(hyunyoung2.github.io)’s Howt get and use MNIST in Tensorflow
BUT, If you want to ust text data, Normally You have to do crawling or get from someone who has the data you want.
In the case of crawling, you also have to parsing the data which you crawled, That is so annoying.
So I will introduce more easy way to get text data with wikipedia.
how to Download and Parse wikipedia.
Wikipedia provide text dump file per languages. Because that data is given as xml format.
you have to parse the xml after download.
If you want to download wikimedia file, vist here, wikimedia.
In my case, I will deal with Korean language. So If you want to download Korean language file, vist kowiki
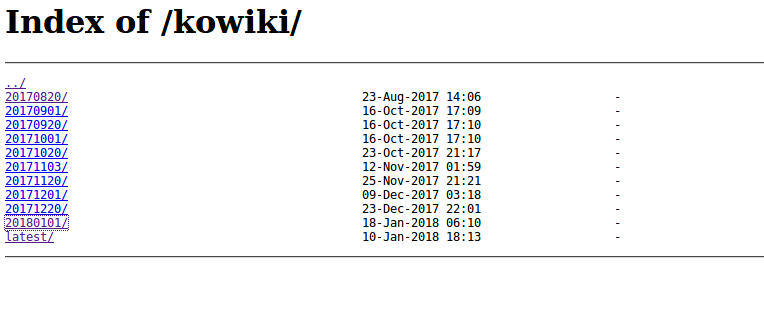
After getting in the URL, click date you want to download.
wikimedia provide a variety of dump files as xml. Basically, I think it is enough to use pages-article.xml.bz2 dump file among the dump files for you.
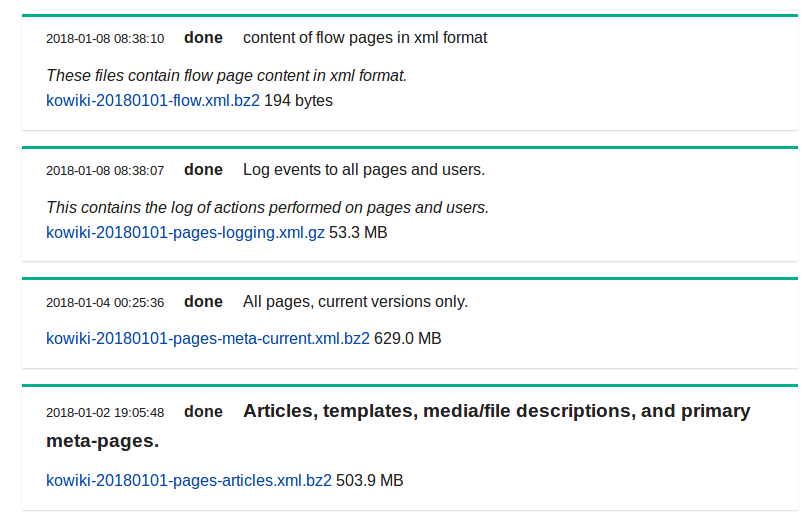
When I made word2vec. I used it from https://dumps.wikimedia.org/kowiki/latest/kowiki-latest-pages-articles.xml.bz2
And If you want to download another language, Just change ko to thing you want in kowiki. i.e ko indicates korean. as en short for english. likewise utilize some word which represents another country language.
When you finish downloading dump file of wikimedia. you have to parse it. But don’t worry about it.
Already someone made it to parse wikimedia file as opensource. I recommend you a opensource, Wikiextractor’s github.
The way to use the opensource is “git clone https://github.com/attardi/wikiextractor.git”
Wikiextractor
The following is the result of running wikiextractor.py with wikimedia dump file.
The resulting file is json or plain text formatted in a number of files of simmilar size in a given directory.
python3 Wikiextractor.py –json
If you invoke wikiextractor.py with –json flag. the resulting format is json object one per line with the following structure.
{"id": "", "revid": "", "url":"", "title": "", "text": "..."}
The following is a portion of wiki_00 under AA directory
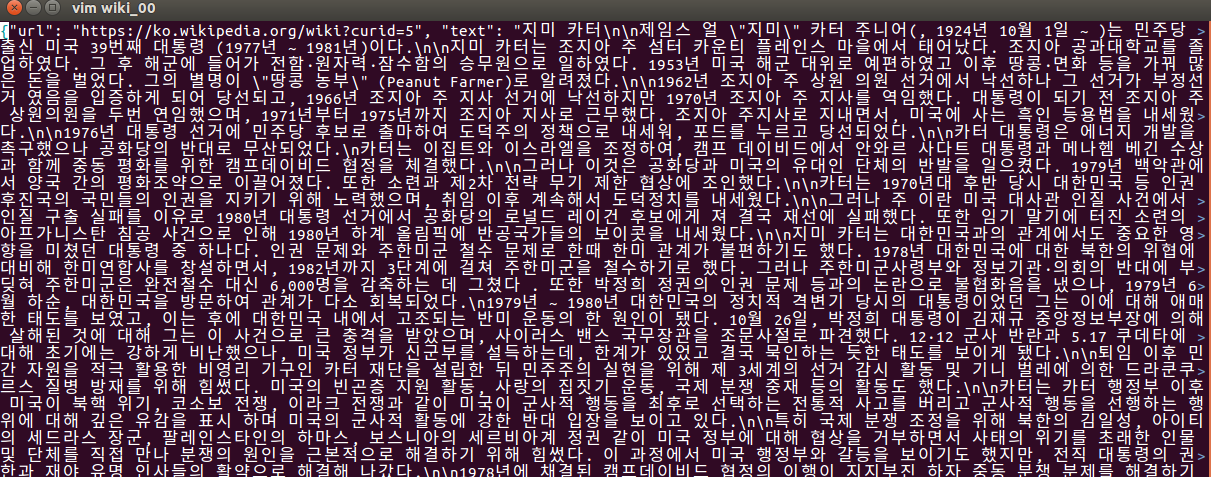
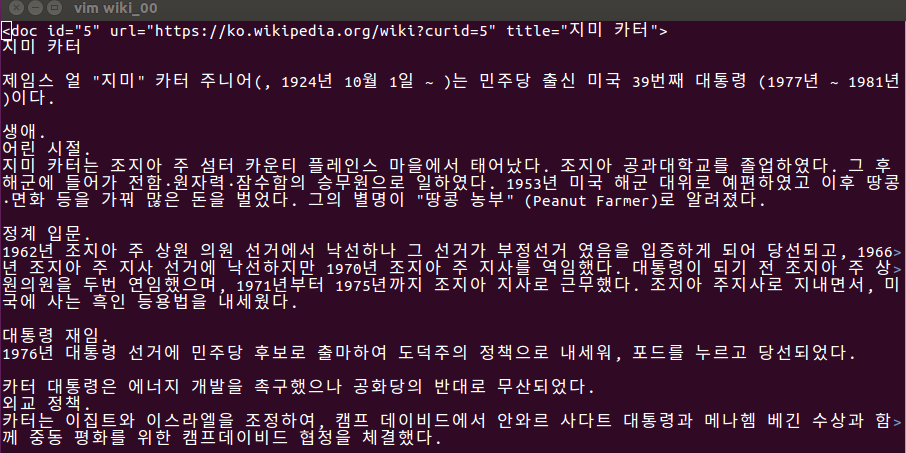
python3 Wikiextractor.py
If you invoke Wikiextractor with no flag, Each file will contain several documents in the format:
<doc id="" revid="" url="" title="">
content(text
</doc>
The following is a portion of wiki_00 under AA directory

The following is the case where you invoke Wikiextractor.py with -l(link), –lists, or -s(section) flag
python3 Wikiextractor.py -l
-l means link, so after parsing, there is link such as a tag of html
The following is a portion of wiki_00 under AA directory
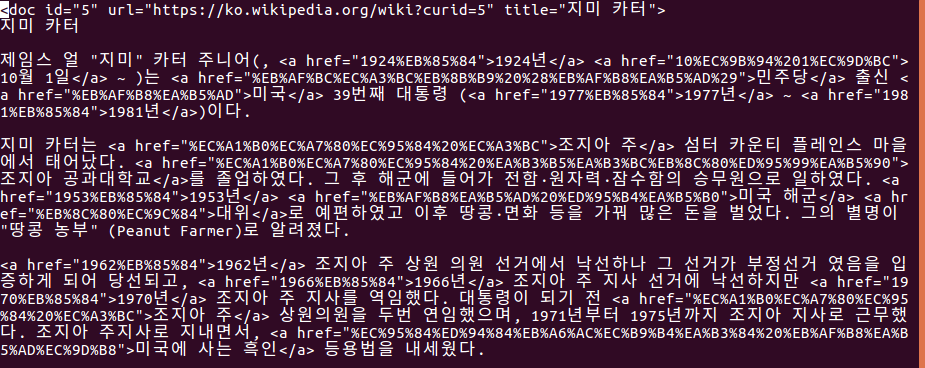
python3 Wikiextractor.py –lists
–lists literally means list, so after parsing, there is list of contents of wikimedia.
The following is a portion of wiki_00 under AA directory
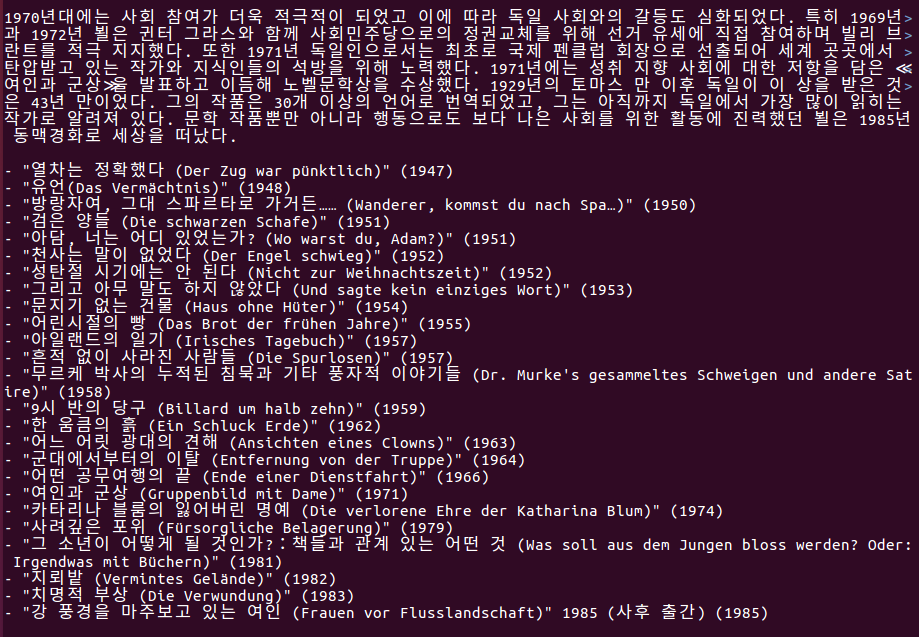
python3 Wikiextractor.py -s
-s means section, i.e. subtitle remaint as parsed.
The following is a portion of wiki_00 under AA directory
If you want to download shell script to automatically download kowikimedia and parse it with Wikiextractor, visit Datasetting-TEXT of hyunyoung2 git rep