The paper, “Linguisitic Regularities in Continuous Space Word Representation (Mikolov et al., NAACL 2013)” explains how to evaluate sytantic and semantic regularities between the induced word vectors, with a form as “king - Man + Woman” result in a vector veryl clost to “Queen”.
i.e. When you evaluate syntatic and semantic regularities with word vector representations in continous space. you have to create a test set of analogy questions of the form “a is to b as c is to ___”. i.e. If you know a, b, and c words. what is ___?
A : B = C : ___
The above computation is so easy. it is observed as constant vetor offsets between pairs of words sharing a particular relationship.
Their relationship is like :
base/comparative/superlative forms of adjectives;
singular/plural forms of commmon nouns;
possessive/non-possessive froms of common nouns;
base, past and 3rd person present tense forms of verbs.
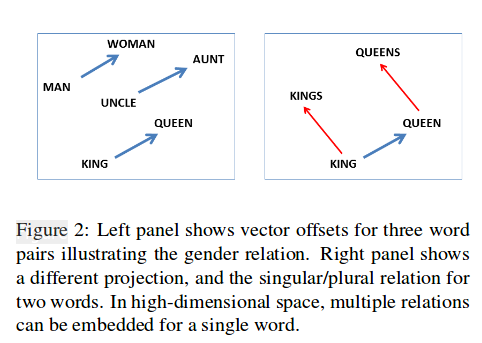
Using vector offsets, this paper tested the relationship of words vector to check how well the vectors represents syntantic and semantic regularities.
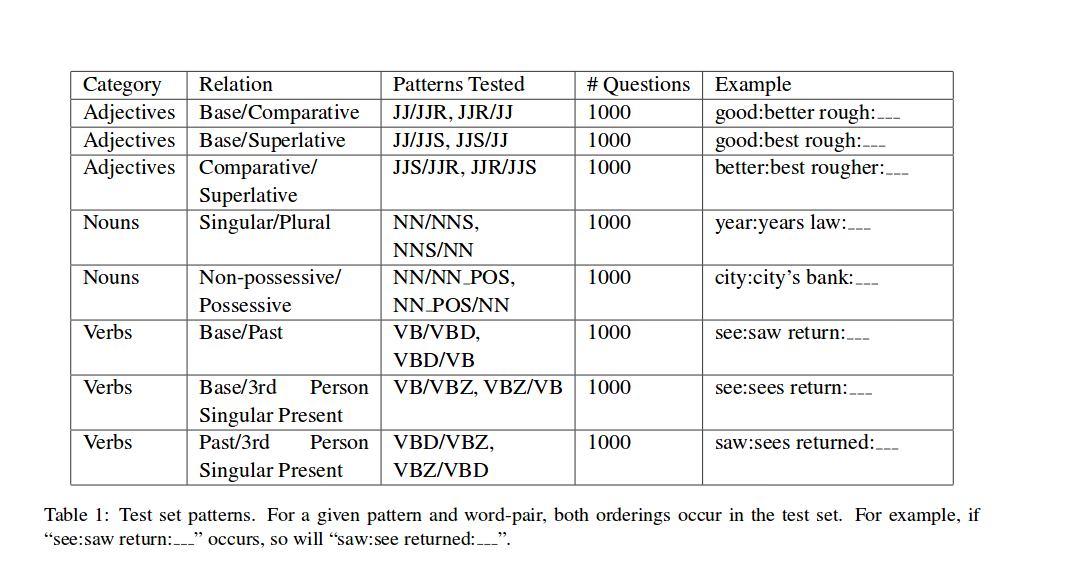
So when they created verification set of words relationship. they used tagged 276M words of newspaper text with PennTreebank POS tags. and they selected 100 of the most frequent comparatives adjectives, (words labeled JJR); 100 of the most frequent plural nouns (NNS); 100 of the most frequent possessive nouns(NN_POS); and 100 of the most frequent base form verbs(VB)
With 100 words from each set of the above thing, they then systematically generated analogy quesions by randomly matching each of the 100 words with 5 other words from the same category, and creating variants as indicated in the above figure, Table 1.
Total test set size is 8000.
To the key point in this paper, the distributed representation by recurrent neural network language model has no knowledge of syntax, morphology or semantics on words. however suprisingly, training such a purely lexical word representations showed striking syntantic and semantic properties.
The paper: Linguistic Regularities in Continous Space Word Representations (Mikolov et al., NAACL 2013)