How To Use Google’s Word2Vec C Source File
How to use Google’s Word2Vec c source file.
you can download Word2Vec c source file from https://code.google.com/archive/p/word2vec/source/default/source.
Also Google’s code archive of Word2Vec is : https://code.google.com/archive/p/word2vec/
How to use it
download
you cannot export this source files to your github, so you just have to download this source files directly.

unzip
After Downloading the above code, uncompress the download file.
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test [17:26:31]
$ ls
source-archive.zip
$ unzip source-archive.zip
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test [17:27:41]
$ unzip source-archive.zip
Archive: source-archive.zip
creating: word2vec/
.......
inflating: word2vec/trunk/distance.c
inflating: word2vec/trunk/word2vec.c
inflating: word2vec/trunk/questions-words.txt
inflating: word2vec/trunk/LICENSE
After unziping source-archive.zip, you can see some directory
I mean word2vec directory is created. so if you enter the directory.
you see a directory, trunk. just continuously enter in.
Finally You find out C source file of word2vec of google
let’s see the processing of what I said above in the following command line :
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test [17:28:03]
$ ls
source-archive.zip word2vec
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test [17:28:49]
$ cd word2vec
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test/word2vec [17:29:04]
$ ls
trunk
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test/word2vec [17:29:05]
$ cd trunk
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test/word2vec/trunk [17:29:10]
$ ls
compute-accuracy.c demo-train-big-model-v1.sh makefile word2vec.c
demo-analogy.sh demo-word-accuracy.sh questions-phrases.txt word-analogy.c
demo-classes.sh demo-word.sh questions-words.txt
demo-phrase-accuracy.sh distance.c README.txt
demo-phrases.sh LICENSE word2phrase.c
Make and a example with demo-analogy.sh
In order to compile the Word2Vec source, use make
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test/word2vec/trunk [17:33:25]
$ make
gcc word2vec.c -o word2vec -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result
gcc word2phrase.c -o word2phrase -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result
gcc distance.c -o distance -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result
.......
chmod +x *.sh
# hyunyoung2 @ hyunyoung2-desktop in ~/my-jupyter/word2vec-of-google/test/word2vec/trunk [17:38:36]
$ ls
compute-accuracy demo-train-big-model-v1.sh makefile word2vec
compute-accuracy.c demo-word-accuracy.sh questions-phrases.txt word2vec.c
demo-analogy.sh demo-word.sh questions-words.txt word-analogy
demo-classes.sh distance README.txt word-analogy.c
demo-phrase-accuracy.sh distance.c word2phrase
demo-phrases.sh LICENSE word2phrase.c
As you can see abvoe, after make command, according to chmod +x *.sh, You can execute all shell scripts.
From now on, let’s walk through a shell scripts.
One of demo shell scripts we are talking about is demo-analogy to find out analogy of the relationship of words like Man - Woman + King = Queen :
$ vim demo-analogy.sh
make
if [ ! -e text8 ]; then
wget http://mattmahoney.net/dc/text8.zip -O text8.gz
gzip -d text8.gz -f
fi
echo ---------------------------------------------------------------------------------------------------
echo Note that for the word analogy to perform well, the model should be trained on much larger data set
echo Example input: paris france berlin
echo ---------------------------------------------------------------------------------------------------
time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
./word-analogy vectors.bin
As you can see the above snippets of all shell scripts. you get a hint of how to make word2vec, it show you a line, “time ./word2vec….” :
time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
Keep in mind, size is the size of your word-embedding. I mean word dimension.
Let’s execute the demo-word.sh
$ ./demo-analogy.sh
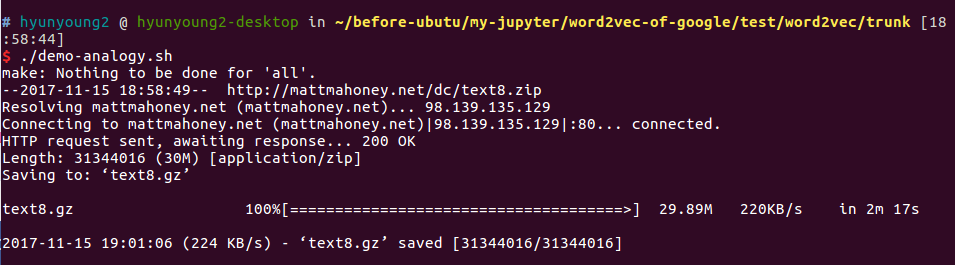
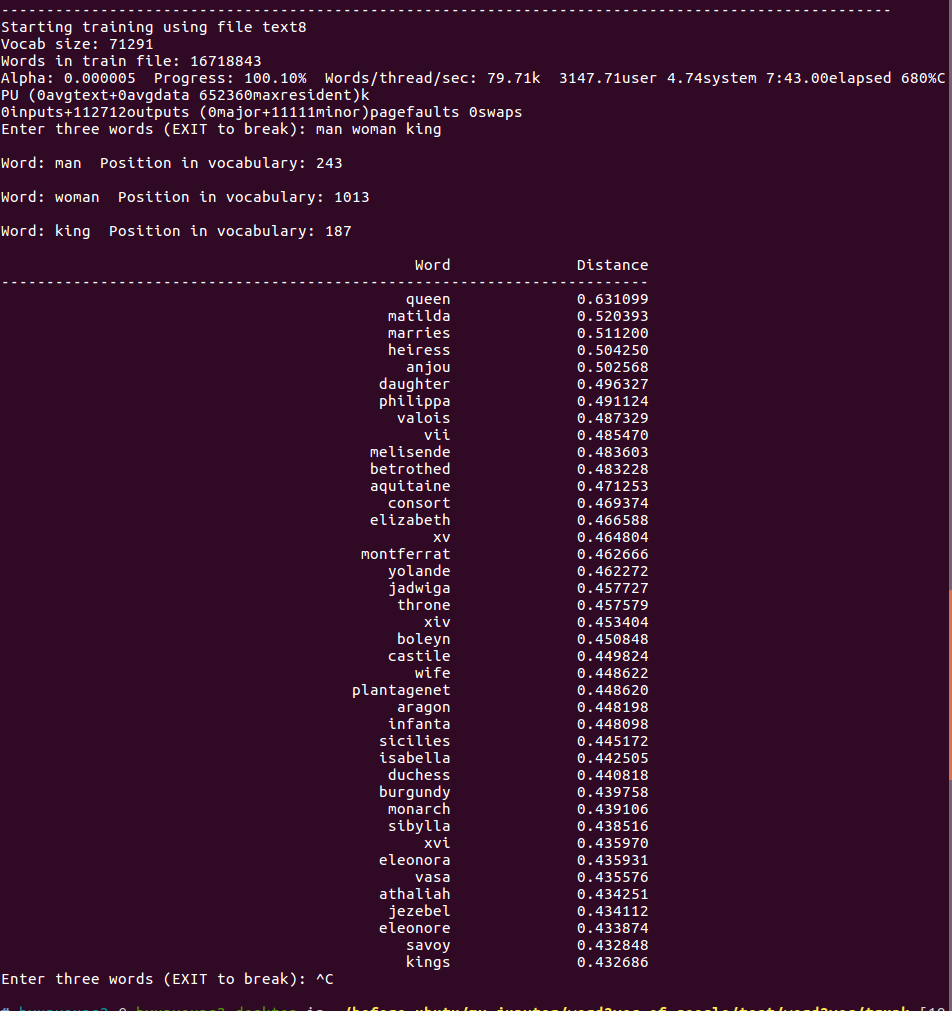
You can also the stat of threads, In this case I used 20 threads. let’s see the state of threads
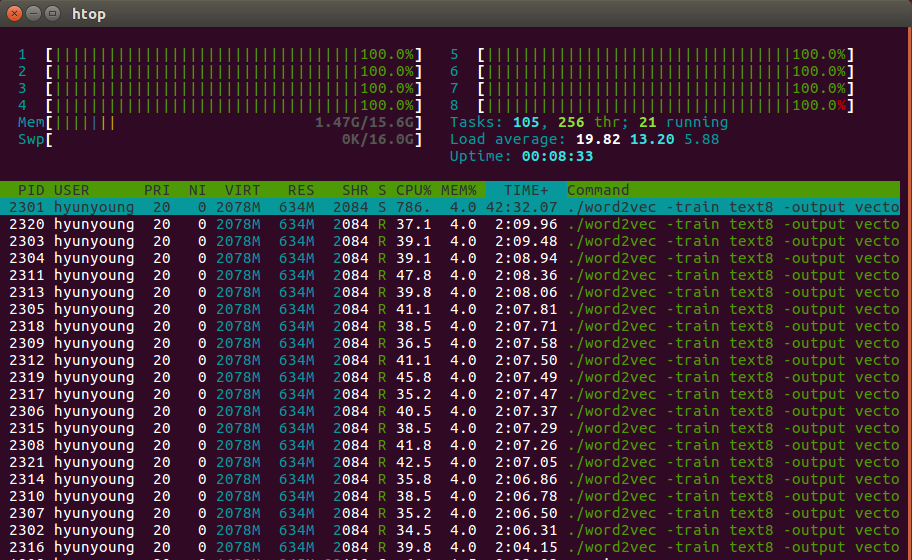
$ ls
$ ls
compute-accuracy demo-train-big-model-v1.sh makefile word2phrase
compute-accuracy.c demo-word-accuracy.sh questions-phrases.txt word2phrase.c
demo-analogy.sh demo-word.sh questions-words.txt word2vec
demo-classes.sh distance README.txt word2vec.c
demo-phrase-accuracy.sh distance.c text8 word-analogy
demo-phrases.sh LICENSE vectors.bin word-analogy.c
as you can see above, you could find out something like vectors.bin and text8(input data file)
thai is file that stores vector values
let’s see the vector file
$ vim vector.bin


as you can see, the file is broken. That is becuase i run the word2vec with binary mode(1).
help message
But you don’t need to analyze shell script. just word2vec executable show you how to use word2vec executable as you type ./word2vec in command line like this :
$ ./word2vec
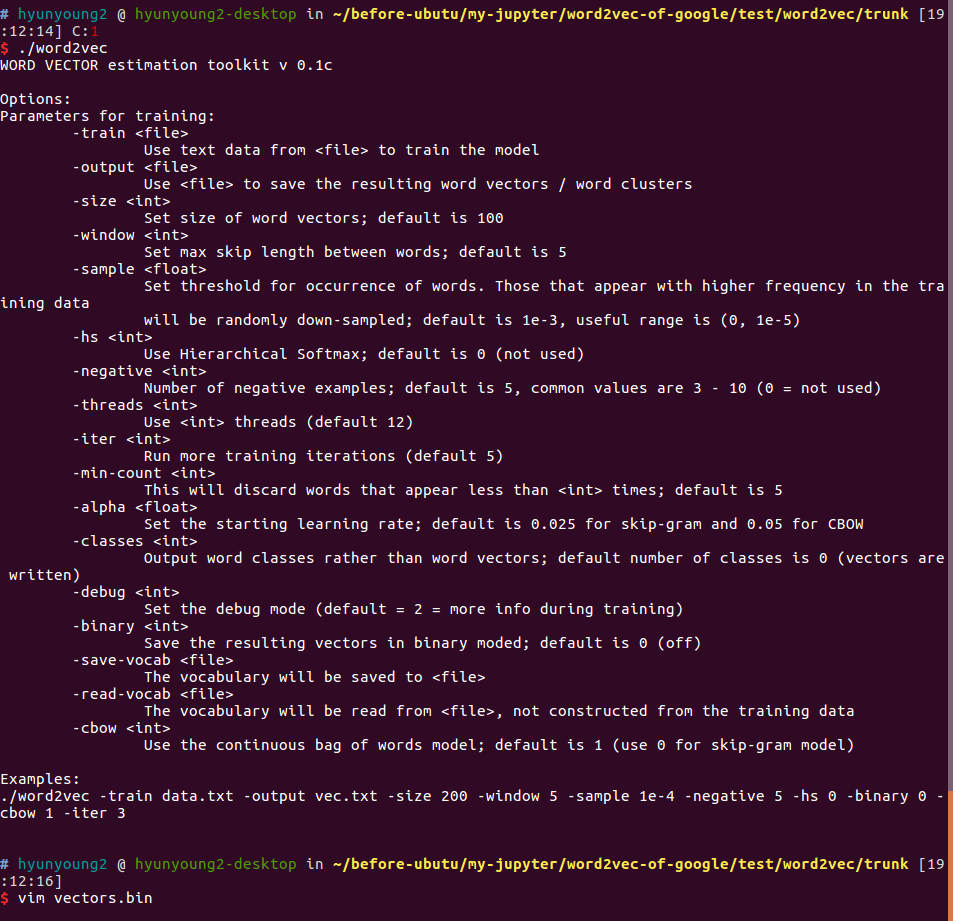
In here, simply speaking about word2vec usage.
-
data.txt means a file you want to train for word embedding
-
binary : whether output is binary or not
Let’s see vector.txt using word2vec of google.
$ time ./word2vec -train text8 -output vec.txt -size 200 -window 5 -sample 1e-4 -negative 5 -hs 0 -binary 0 -cbow 1 -iter 3
# hyunyoung2 @ hyunyoung2-desktop in ~/before-ubutu/my-jupyter/word2vec-of-google/test/word2vec/trunk [19:16:18] C:1
$ ./word2vec -train text8 -output vec.txt -size 200 -window 5 -sample 1e-4 -negative 5 -hs 0 -binary 0 -cbow 1 -iter 3
Starting training using file text8
Vocab size: 71291
Words in train file: 16718843
Alpha: 0.000005 Progress: 100.03% Words/thread/sec: 298.74k %
$ vim vec.txt
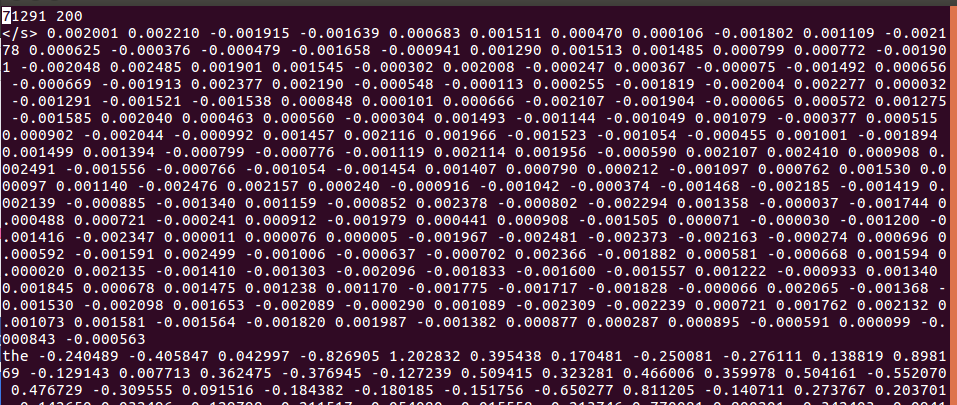
As you can see above, you can check the total number of word vector’ and dimensions of a word. and then you can identify the vector value of a word like this :
71291(total count of word vector) 200(dimension of a word)
The following is vector value of </s>
</s> 0.002001 0.002210 -0.001915 -0.001639 0.000683 0.001511 0.000470 …….
71291 : means the total number of word vector.
200 : means the number of dimension of a word
0.002001 0.002210 ……. : means vector of word