this article refers to this open source(NVMe Cli),nvme-cli, related to Nvme.
this is made of what I studied with open source, nvme-cli.
I am analyzingin the most basic command, read, write, dataset command.
and, in addition, If you see the specification(NVM_Express_1_2) of nvme, It would be much better.
Analyse Open Source (nvme-cli-0.7-release version)
Read
this command is nvme read /dev/nvme0n1(nvme device) -s -c -z -d …
- function flow
static int read_cmd(int argc, char ** argv)
{
...
return submit_io(nvme_cmd_read, "read", desc, argc, argv);
}
static int submit_io(int opcode, char *command, const char *desc, int argc, char **argv)
{
struct timeval start_time, end_time;
void * buffer, * mbuffer = NULL;
int dfd, mfd;
int flags = opcode & 1 ? O_RDONLY : O_WRONLY | O_CREAT;
int mode = S_IRUSR | S_IWUSR |S_IRGRP | S_IWGRP| S_IROTH;
__u16 control = 0;
// mainly about variable I see carefully
cfg.start-block (__u64), cfg.blockcount (__u16), cfg.data_size(__U64), cfg.data (char *)
parse_and_open(argc, argv, desc, command_line_options, &cfg, sizeof(cfg));
dfd = mfd = opcode & 1 ? STDIN_FILENO : STDOUT_FILENO; // file descriptor configuration
// function call
err = nvme_io(fd, opcode, cfg.start_block, cfg.block_count, control, 0,
cfg.ref_tag, cfg.app_tag, cfg.app_tag_mask, buffer, mbuffer);
...
}
int nvme_io(int fd, __u8 opcode, __u64 slba, __u16 nblocks, __u16 control,
__u32 dsmgmt, __u32 reftag, __u16 apptag, __u16 appmask, void *data,
void *metadata)
{
struct nvme_user_io io = {
.opcode = opcode, // opcode of submit_io function
.flags = 0, // defalut value
.control = control, // control variable of submit_io function
.nblocks = nblocks, // block_count of submit_io function
.rsvd = 0, // defalt value
.metadata = (__u64)(uintptr_t) metadata, // filename of sumbit_io function
.addr = (__u64)(uintptr_t) data, // filename of sumbit_io function
.slba = slba, // start_block of submit_io function
.dsmgmt = dsmgmt, // 0 of submit_io function
.reftag = reftag, // ref_tag of submit_io function
.appmask = apptag, // app_tag of submit_io function
.apptag = appmask, // app_tabg_mask of submit_io function
};
return ioctl(fd, NVME_IOCTL_SUBMIT_IO, &io);
}
now the statements above show you variable mathcing between submit_io function and nvme_io function
may when comparing nvme-cli open source with nvme specification 1.2, those are different.later on, If I use this open source on nvme specification 1.2, this need to be fixed a little bit.
- Read command of nvme specifictaion 1.2
now nblocks, slba in the above instruction is important.
so In nvme specification 1.2, definition of slba the following is start LBA (SLBA) : This field indicateds the 64-bit address of the first of logical block to be read as part of the operation. Command Dword 10 contains bits 31:00 ; command Dword 11 contains bits 63:32
Write
this command is nvme write /dev/nvme0n1(nvme device) -s -c -z -d …
- function flow
static int writ_cmd(int argc, char ** argv)
{
return submit_io(nvme_cmd_read, "write", desc, argc, argv);
}
static int submit_io(int opcode, char *command, const char *desc, int argc, char **argv)
{
struct timeval start_time, end_time;
void * buffer, * mbuffer = NULL;
int dfd, mfd;
int flags = opcode & 1 ? O_RDONLY : O_WRONLY | O_CREAT;
int mode = S_IRUSR | S_IWUSR |S_IRGRP | S_IWGRP| S_IROTH;
__u16 control = 0;
// mainly about variable I see carefully
cfg.start-block (__u64), cfg.blockcount (__u16), cfg.data_size(__U64), cfg.data (char *)
parse_and_open(argc, argv, desc, command_line_options, &cfg, sizeof(cfg));
dfd = mfd = opcode & 1 ? STDIN_FILENO : STDOUT_FILENO; // file descriptor configuration
// function call
err = nvme_io(fd, opcode, cfg.start_block, cfg.block_count, control, 0,
cfg.ref_tag, cfg.app_tag, cfg.app_tag_mask, buffer, mbuffer);
// next write to filedesriptor
if (err < 0)
perror("submit-io");
else if (err)
printf("%s:%s(%04x)\n", command, nvme_status_to_string(err), err);
else {
fprintf(stderr, "befer writ function\n");
if (!(opcode & 1) && write(dfd, (void *)buffer, cfg.data_size) < 0) {
fprintf(stderr, "failed to write buffer to output file\n");
err = EINVAL;
goto free_and_return;
} else if (!(opcode & 1) && cfg.metadata_size &&
write(mfd, (void *)mbuffer, cfg.metadata_size) < 0) {
fprintf(stderr, "failed to write meta-data buffer to output file\n");
err = EINVAL;
goto free_and_return;
} else
fprintf(stderr, "%s: Success\n", command);
}
}
int nvme_io(int fd, __u8 opcode, __u64 slba, __u16 nblocks, __u16 control,
__u32 dsmgmt, __u32 reftag, __u16 apptag, __u16 appmask, void *data,
void *metadata)
{
struct nvme_user_io io = {
.opcode = opcode, // opcode of submit_io function
.flags = 0, // defalut value
.control = control, // control variable of submit_io function
.nblocks = nblocks, // block_count of submit_io function
.rsvd = 0, // defalt value
.metadata = (__u64)(uintptr_t) metadata, // filename of sumbit_io function
.addr = (__u64)(uintptr_t) data, // filename of sumbit_io function
.slba = slba, // start_block of submit_io function
.dsmgmt = dsmgmt, // 0 of submit_io function
.reftag = reftag, // ref_tag of submit_io function
.appmask = apptag, // app_tag of submit_io function
.apptag = appmask, // app_tabg_mask of submit_io function
};
return ioctl(fd, NVME_IOCTL_SUBMIT_IO, &io);
}
now the statements above show you variable mathcing between submit_io function and nvme_io function may when comparing nvme-cli open source with nvme specification 1.2, those are different.
later on, If I use this open source on nvme specification 1.2, this need to be fixed a little bit.
- write command of nvme specifictaion 1.2
now nblocks, slba in the above instruction is important.
so In nvme specification 1.2, definition of slba the following is start LBA (SLBA) : This field indicateds the 64-bit address of the first of logical block to be read as part of the operation. Command Dword 10 contains bits 31:00 ; command Dword 11 contains bits 63:32
- write command of nvme specifictaion 1.2
dataset management
this command is nvme dsm /dev/nvme0n1(nvme device) -s -n -d …
- function flow
static int dsm(int argc, char **argv)
{
uint16_t nr, nc, nb, ns;
int ctx_attrs[256] = {0,};
int nlbs[256] = {0,};
unsigned long long slbas[256] = {0,};
struct nvme_dsm_range *dsm;
// mainly about variable I see carefully
cfg.blocks (char *), cfg.slbs (char *), cfg.ad(int)
parse_and_open(argc, argv, desc, command_line_options, &cfg, sizeof(cfg));
nc = argconfig_parse_comma_sep_array(cfg.ctx_attrs, ctx_attrs, array_len(ctx_attrs));
nb = argconfig_parse_comma_sep_array(cfg.blocks, nlbs, array_len(nlbs));
ns = argconfig_parse_comma_sep_array_long(cfg.slbas, slbas, array_len(slbas));
nr = max(nc, max(nb, ns)); //total length of dsm command in nvme-cli
if (!cfg.cdw11)
cfg.cdw11 = (cfg.ad << 2) | (cfg.idw << 1) | (cfg.idr << 0);
dsm = nvme_setup_dsm_range((__u32 *)ctx_attrs, (__u32 *)nlbs, (__u64 *)slbas, nr);
err = nvme_dsm(fd, cfg.namespace_id, cfg.cdw11, dsm, nr);
if (err < 0) {
fprintf(stderr, "error:%x\n", err);
return errno;
} else if (err != 0)
fprintf(stderr, "NVME IO command error:%s(%x)\n",
nvme_status_to_string(err), err);
else
printf("NVMe DSM: success\n");
return 0;
}
- dsm (dataset management of nvme specification 1.2)
about Dataset Management command The Dataset Management command is used by the host to indicated attributes for ranges of logival blocks. This includes attributes like frequency that data is read, or wrtten, access size, and other information that may be used to optimize performance and reliability. This command is advisory; a compliant controller may choose to take on action based on information provided
for example of erase :
# erase 1 block (vblock 120, die 44)
[root@localhost nvme-cli]# nvme dsm /dev/nvme0n1 -s (address of vblock 120, die 44) -b 0 -d
NVMe DSM: success
# erase 2 blocks with 1 command (vblock 120, die 44) and (vblock 853, die 12)
[root@localhost nvme-cli]# nvme dsm /dev/nvme0n1 -s (address of vblock 120, die 44),(address of vblock 853, die 12) -b 0,0 -d
NVMe DSM: success

The data that The Dataset Management command provides is a list of ranges with context attributes. Each range consists of a starting LBA, a length of logical blocks that the range consists fo and the context attributes to be applied to that range.
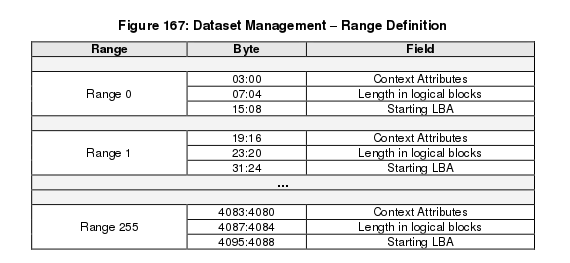
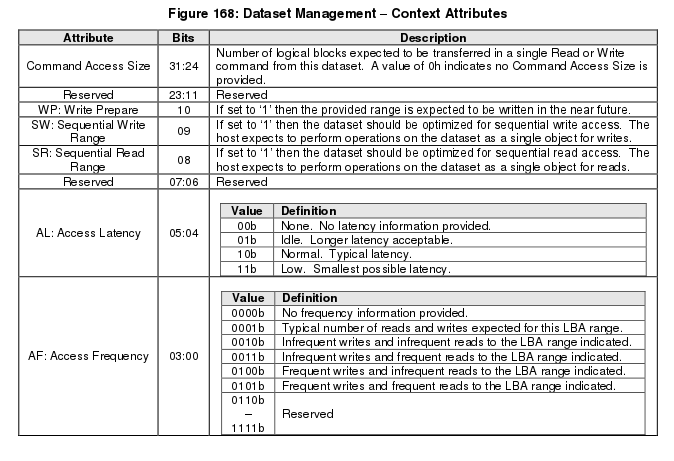
The context attributes specified for each range provides information about how the range is intended to be used by host software. The use of this command is optional and the controller is not required to perform any specific action.
as for Deallcat An LBA that has been deallocated using the Dataset Management command is no longer deallocated when The LBA is written. Read operarions do not affect the deallocation status of an LBA. The value read from a deallocated LBA shall be deterministic; specifically, the values returned by subsequent reads of that LBA shall be the same until a write occurs to that LBA. The values read from a deallocated LBA and its metadata (excluding protection information) shall be all zeros, all onesm or the last data written to the associated LBA and its metadata. The values read from a deallocated or unwrtten LBA’s protection information field shall be all ones
Theory about linux and C
C languge
#endef
this opensource is using “#define” and “#undef”
- Syntax
#undef
identifier
briefly, The #undef directiv removes ther current of identifier. Consequently, subsequent occurences of identifier are ignored by the preprocessor. To remove a macro definition using #undef, giv only the macro identifier ; do not give a pararmeter list.
You can also apply the #undef directive to an identifier that has no previous definition. This ensures that identifier is undefined. Macro replacement is not performed within #undef statements.
The #undef directive is typically paired with a #undef directive to create a region in a source program in which an identifier has a special meaning. For example, a specific function of the source program can use manifest constants to define evironment-specific values that do not affect the rest of the program. The #undef directive also works with the #if directive to control conditional compliation of the source program.
In the following example, the #undef directive removes definitions of a symbolic constant and a macro. Note that only the identifier of the macro is given.
#define WIDTH 80
#define ADD( X, Y) ((x) + (y))
.
.
.
#undef WIDTH
#undef ADD
Initialization of struct of C language in kernel
this article below is made referring to this site
basically, way to initialize variable of structure, the following shows you initialization of struct in Kernel
struct student {
int roll;
int class;
char name[50];
};
Now, let’s declare a variable st3 and intialize using the third method.
first, here is :
student st3={
.name = "Mark", //Notice the equal to and the comma
.class = 10,
.roll = 1038
};
Basename
this article is made by refering to this site(basename)
-
What is basename
when you provide a string that contains a filename with full path, basename will remove only the directory portion of it, and return only the file name portion of that string, It can also remove that file extension, and return only the filename without an extension.
-
Briefly, Example
$ basename /etc/passwd passwd
If file has extension :
$ basename /usr/local/apache2/conf/http.conf httpd.conf
If you get only filename without extension
$ basename /usr/local/apach2/conf/httpd.conf .conf httpd
-
Syntax and Options
basename NAME [SUFFIX] basename OPTION
fstat function
fstat(int fd, struct stat *buf) is used to get the status of file. the status is useful informations.
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* inode number */
mode_t st_mode; /* protection */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
dev_t st_rdev; /* device ID (if special file) */
off_t st_size; /* total size, in bytes */
blksize_t st_blksize; /* blocksize for file system I/O */
blkcnt_t st_blocks; /* number of 512B blocks allocated */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last status change */
};
If you want to know more about fstat, let’s click here(fstat)
Information, aligned memory
memory is aligned is senstive. If you want to know more about this information, just let’s visit this site(stackoverflow) and then If you can not understand the aligned memory, let’s vistie this site(unaligned-memory-access) one more time
If you see specification of nvme, on page invovle with PRP, You can get hint that alignment is important.
The controller may support several physical formats of logical block size and associated metadata size. There may be performance difference between different physical formats. This is indicated as part of the Identify Namespace datat structure.
the linux command
during operating and fixing open source, nvme-cli, I noticed many thing about linux commands.
So here is arrangment of linux command I realized.
- dd
> dd command stands for "data duplicator" and used for copying and converting data. It is very powerful low level utility of Linux which can do much more.
>
> If you want to know more about dd command, I recommend [this site(linuxnix)](http://www.linuxnix.com/what-you-should-know-about-linux-dd-command/) and [another site(linoxide)](http://linoxide.com/linux-command/linux-dd-command-create-1gb-file/) and [another site of stack overflow](http://superuser.com/questions/797664/whats-the-difference-between-dds-command-options-bs-1024-count-1-and-bs-1-coun)
- echo $?
this command is you can check command works well,
- diff vs vimdiff
diff means in the command line, you can indentify difference with files.
Basically, you want to use this command, I recommend you this site(livefirelabs) But, for hex dump file, recommend you this site(stackoverflow)
vimdiff
you can use vim and diff together.
you want to use this command, I recommend you this site(vimdiff) and another site(github)
- grep
this command is what I like. when I’m searching for word. The following is basic sample.
$ grep -nir ab *
Binary file argconfig.o matches
completions/README:3:Setting Up NVMe Tab Autocompletion for bash or zsh
completions/README:20:you should be able to autocomplete with the nvme utility now
- xxd filename
this command give you hexa dump file of filename.
If you want to know more about this command, just I recommend you to visit this site(atomicobject) and another site(linoxide)
I/O redirection in linux command line
I refer to this site(linuxcommand) for making a note of the following article.
I would like to recommend one more thing, just I want you to visit this site(digitalocean)
you can be comportable , by using some specail notation you can redirect the outpur of many commands to file, devices, and even to the input of other commands in linux.
- Standard output
This standard output directs its contents to the display. To redirect standard output to a file, the “>” character is used > like this : ls > file_list.txt
In this example, the ls command is executed and the results are written in a file named file_list.txt. since the output of ls was redirected, file_list.txt is overwritten from the beginning with the output of the command ls. If you want the new results to be appended to the file instead, use “»”
- Standard input
This standard input gets its contents from the key usually, but It can be redirected. To redirect standar input from a file instead of the keyboard. the “<” character is used. like this : sort < file_list.txt
In the above example, We used the sort command to process the contents of file_list.txt. The results are output on the display Since The standard output is not redirected in this example. We could redirect standard output to another file like this : sort < file_list.txt > sorted_file_list.txt
As you can see, the above command can have both its input and output redirected. Be aware that the order of the redirection does not matter. The only requirement is that the redirection operators ( the “<” and “>”) must appear after the other options and arguments in the command.
- Pipes
By far, The most useful and powerful thing you can do with I/O redirection is to connect mutilple commands together with what are called pipes. with pipes, the standard output of one command is fed into the standard input of another. here is my absolute favorite :
ls -l | less
In this example, the output of the ls command is fed into less. by using this “| less” trick, you can make any command have scrolling output. I use this technique all the time
special file of linux
- /dev/random or /dev/urandom
This is the linux kernel’s built-in Random Number gernerator /dev/{u}random are accalimed for producing reliable random data providing the same security level that is used for the creation of cryptographic keys. If you want to know more about this, just vist this site(Random_number_generation)
- /dev/zero & /dev/null
/dev/zero
this is used to create dummy file. /dev/zero produces a continuous stream of NULL(zero value) bytes.
/dev/null
/dev/null produces no output If you are short of your ambition about acquiring knowledge. how about visiting this site(stackexchange)
command in vim
If you wnat to know vim command easily, what about visiting this site(searching)
- /pattern & ?patter
If you want to search for the particular pattern, use this command. then press keyword “n,N” -> command mode.
- *
likewise, this command is , when you search for the particular pattern, what you have to use.
- :linenumber
this command is, when you search for the particular line, then you do have to use this command eventually, If you want to know more about this, vim. why don’t you visit this site(Jump_to_a_line_number)
- G (press ESC and type in upper case G) : this jump to end of file
You can save lots of time by using appropriate movement commands in vi or vim text editor.
For large file the cursor keys are not the best choice. To move to end of file just type G (press ESC and type in upper case G)
- 1G (after press ESC) or gg (after press ESC) > > You can jump back to beginning of file by typing any one for the above commands.
- 700G (after press ESC) > > You can jump to line number 700 > IF you want to see the site explaining the above three commands. > I recommend you [this site(howto-unix-linux-vi-vim-jump-to-end-of-file)](http://www.cyberciti.biz/faq/howto-unix-linux-vi-vim-jump-to-end-of-file/)
test file
printf 'HelloWorld\n%.0s' {1..5} is useful when I generate file With I/O indirection
tip to use the vim
I want you to refer to [this site(stackoverflow)](http://stackoverflow.com/questions/563616/vim-and-ctags-tips-and-tricks)
another diffrent commands for process management and vim
- ps aux
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 191636 5044 ? Ss Sep20 0:19 /usr/lib/system
- <strong>top</strong>
top - 11:16:44 up 6 days, 1 min, 9 users, load average: 1.75, 1.57, 1.47
Tasks: 215 total, 1 running, 214 sleeping, 0 stopped, 0 zombie
%Cpu(s): 16.2 us, 16.3 sy, 0.0 ni, 67.3 id, 0.1 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 8062096 total, 724480 free, 1795520 used, 5542096 buff/cache
KiB Swap: 8126460 total, 7857316 free, 269144 used. 4918576 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
752 root 20 0 4376 512 484 S 21.3 0.0 969:29.59 rngd
If you want to know more, I recommend “htop”
- tabe .
” ============================================================================
“ Netrw Directory Listing (netrw v149)
“ /home/hyunyoung.lee
“ Sorted by name
“ Sort sequence: [\/]$,<core\%(.\d+)=>,.h$,.c$,.cpp$,~=*$,*,.o$,.obj$,.info$,.swp$,.bak$,~$
“ Quick Help::help -:go up dir D:delete R:rename s:sort-by x:exec " ============================================================================