이 글의 내용은 윤성우의 열혈자료구조를 참조했습니다.
data struct is to present data from real world.
in general, there are a variety of data structure,”array, List, queue, dequeue, tree, graph and so on”.
also, above kinds is divided into either linear or non-linear.
there are many data structure nowadays. First, now I will study basic of data structure, “List”.
모든 데이터 구조는 기본적으로 1. 저장 2. 삭제 3. 검색(참조) 와 같은 세가지 기능으로 이루어져 있다.
그리고 List의 경우 배열기반과 메모리 동적 할당을 통한 연결리스트로 구분되어져 있다.
그럼 이에 맞게 자기가 사용할 방식으로 설정을 하고 정의를 하면 된다
즉, 먼저 main 함수 부분에서 자기가 잘 어떠한 형식으로 리스트를 활용할지 그에 대한 함수를 위의 3가지 기본 기능 + 추가 기능을 설정하면된다.
-
배열기반 리스트를 설계해보자. 즉 ArrayList ADT설정
- 리스트 생성 및 초기화
- 삽입부분
- 삭제부분
- 추가 기능 (처번째 원소 탐색 기능 + 현재 위치에거 다음 탐색 기능 + 리스트에 포함된 원소의 갯수)
- 중복 데이터 삽입가능 —-> 이런 것은 모든 자료구조 설정시 설정을 한다면 좋은 방법일듯 하다.
1-1. 리스트 초기화 부분
- void ListInit(List *plist)
- 초기화 할 리스트의 주소 값을 전달한다.
- 리스트 생성 후 제일 먼저 호출되어야 하는 함수 이다.
1-2. 리스트 삽입 부분
- void LInsert(List * plist, LData data)
- 리스트에 데이터를 저장한다. 매개변수 data에 전달된 값을 저장한다.
- 여기서 선택 맨뒤에 저장 or 맨 앞에 저장 or 정렬하면서 저장
1-3. 추가 기능(저장된 데이터의 탐색 초기화)
- int LFirst(List * plist, LData * pdata)
- 첫번째 데이터가 pdata가 가리키는 메모리에 저장된다.
- 데이터의 참조를 위한 초기화 진행된다.
- 참조 성공시 TRUE(1), 실패 시 FALSE(0) 반환
- int LNext(List * plist, LData * pdata);
- 참조된 데이터의 다음 데이터가 pdata가 가리키는 메모리에 저장된다.
- 순차적인 참조를 위해서 반복호출이 가능하다.
- 참조를 새로 시작하려면 먼저 위의 함수 LFirst함수를 호출해야 한다.
- 참조 성공시 TRUE(1), 실패 시 FALSE(0) 반환
* LData는 저장 대상의 자료형을 결정할 수 있도록 typedef로 선언된 자료형의 이름이다.
1-4. 리스트 삭제 부분
- LData LRemove(List * plist)
- LFirst 또는 LNext 함수의 마지막 반환 데이터를 삭제한다.
- 삭제된 데이터는 반환된다.
- 마지막 반환 데이터를 삭제하므로 연이은 바복호출을 허용하지 않는다.
1-5. 추가기능 (리스트에 저장되어 있는 원소의 수)
- int LCount(List * plist)
- 리스트에 저장되어 있는 데이터 수를 반환한다.
위의 배열리스트 ADT를 가지고 코드화 한다면 아래와 같다.
// c 언어 기반 정의
#define TRUE 1
#define FALSE 0
// 기본적인 자료구조 정의
#define LIST_LEN 100
typedef int LData;
typedef struct __ArrayList
{
LData arr[LIST_LEN];
int numOfData; // 리스트에 저장된 데이터의 수
int currPosition; // 마지막 참조 위치에 대한 정보 저장
}ArrayList;
typedef ArayList List;
// 이제 기능들 정의 차례
// 리스트 초기화
void ListInit(List * plist)
{
(plist -> numOfData)= 0;
(plist -> curPosition) = -1;
// -1은 아무것도 참조하지 않았음을 의미한다.
}
/* 여기서 중요한 것은 초기화 함수의 구성은 구조체 정의 기반으로 한다는 것이다.*/
// 리스트에 데이터 저장
void LInsert(List * plist, LData data)
{
if(plist -> numOfData > LIST_LEN) // 저장 할 공간이 없다면
{
puts("저장이 불가능합니다.\n");
return;
}
plist -> arr[plist -> numOfData] = data; // 데이터 저장
(plist -> numOfData)++; // 저장된 데이터의 수 증가
}
// 추가 기능 첫번째 데이터를 참조
int LFirst(List *plist, LData * pdata)
{
if(plist -> numOfData == 0) // 저장된 데이터가 하나도 없다면
return FALSE;
(plist->curPosition) = 0; /// 참조 위치 초기화 즉, 첫번째 데이터의 참조를 의미!
*pdata = plist -> arr[0]; // pdata가 가리키는 공간에 데이터 저장
return TRUE;
}
// 중간 부터 다시 처음 부터 참조를 원하면 위의 함수를 호출하면 된다.
// 추가 기능 첫번째 데이터 참조 후 두번째 데이터 참조
int LNext(List * plist, LData * pdata)
{
if(plist -> curPosition >= (plist -> numOfData) -1) // 더 이상 참조할 데이터가 없다면
return FALSE;
(plist -> curPosition)++;
*pdata = plist -> arr[plist-> curPosition];
return TRUE;
}
// *key point 값의 반환을 매개변수로 한다는 거 !!! 함수 리턴은 성공여부를 알리기 위해
// 리스틀의 삭제 부분, 단 이 함수는 마지막에 참조된 원소만 삭제
LData LRemove(List * plist)
{
int rpos = plist -> curPosition; // 삭제할 데이터의 인덱스 값 참조
int num = plist -> numOfData;
int i;
LData rdata = plist -> arr[rpos]; // 삭제할 데이터 임시로 저장
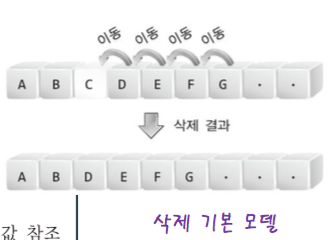
// 삭제를 위한 데이터의 이동을 진행하는 반복문
for (i = rpos ; i < num -1 ; i++)
plist -> arr[i] = plist -> arr[i+1];
// 위의 부분이 배열을 쓰면 항상 연산 속도에 영향을 주는 부분
(plist -> numOfData)--; // 데이터 수 감소
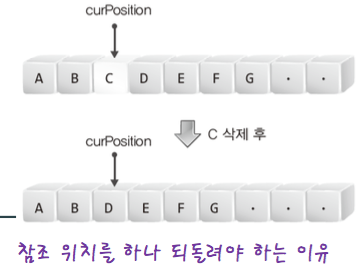
(plist -> curPosition)--; // 중요 앞으로도 즉, 삭제한 원소의 전부분을 참조하도록
return rdata; // 삭제된 데이터 반환
}
// 리스트 삭제
// 참조위치를 전의 위치로 하는 이유
// 리스트의 원소의 수를 반환한다.
int LCount(List * plist)
{
return plist -> numOfData;
}
아래는 main 함수에서 위의 함수들이 어떻게 불리는지 보여주는 것이다.
// 리스트 초기화
int main (void)
{
List list; // 리스트 생성
.......
ListInit(&list); // 리스트 초기화
.......
}
//초기화된 리스트에 데이터 저장
int main(void)
{
.......
LInsert(&list, 11); //리스트에 11을 저장
LInsert(&list, 22); //리스트에 22를 저장
LInsert(&list, 33); //리스트에 33을 저장
.......
}
/// 리스트의 데이터 참조과정
int main(void)
{
.....
if(LFirst(&list, &data)) /// 첫 번째 데이터 변수 data에 저장
{
printf("%d " , data);
while(LNext(&list, &data)) /// 두번째 이후 데이터 변수 data에 저장
print("%d", data);
}
......
}
// 데이터 참조의 일련의 과정
// LFirst -> LNext -> LNext -> LNext .......
// 리스트 데이터의 삭제
int main(void)
{
..... // LRemove 함수는 연이은 호촐을 허용하지 않도록 설계
if(LFirst(&list, &data))
{
if(data == 22) // 위의 LFirst 함수를 통해 참조한 데이터 삭제!
LRemove(&list);
while(LNext(&list, &data))
{
if(data == 22)
LRemove(&list); /// 위의 LNext 함수를 통해 참조한 데이터 삭제!
}
}
............
}
최종마무리
2-1. ArrayList 단점
- 배열길이가 초기에 결정되어야 한다. 변경이 불가능하다.
- 삭제의 과정에서 데이터의 이동(복사)가 매우 빈번히 일어난다.
2-2. ArrayList 장점
- 데이터 참조가 쉽다. 인덱스 값 기준으로 어디든 한번에 참조 가능!