This post is a brief summary about the paper that I read for my study and curiosity, so I shortly arrange the content of the paper, titled How Can We Know What Lnaguage Models Know? (Jiang et al., TACL 2020), that I read and studied.
They guage the knowledge of langauge with prompt as follows:
But they focused on the prompt style based on the paper titeled as Language models as knowledge base? (Petroni et al. EMNLP 2019)
The style of prompt is retained, but the quality of prompt is improved.
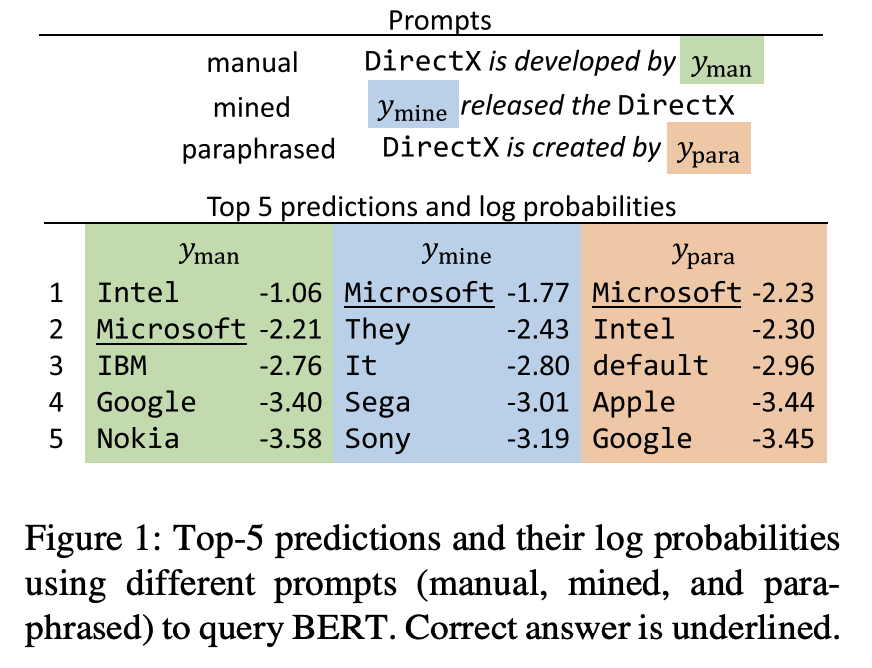
They propose the method of prompt genration like both Mining-based generation and Paraphrasing-base generation.
-
The mining-based generation uses the cooccurence words between subject and object, and the other mining-based generation is the dependecy-based prompts.
-
The paraphrasing-based generation denotes the original prompt into other semantically similar or identical expressions, so they used back-translation for paraphrasing method.
In order to verify the knowledge of language model, they generate the improved prompts and also test to exctract th knowledge using ensembling at the test time for the knowledeg of language model.
For the verified method with the generated prompts at test tiem, they propsoe the three methods as follows:
-
Top 1 Prompt Selection
-
Rang-based Enemble
-
Optimized Ensemble
You can see the detailed empirical analysis and experiemtn in the paper, titled How Can We Know What Lnaguage Models Know? (Jiang et al., TACL 2020)
For detailed experiment and explanation, refer to the paper, titled How Can We Know What Lnaguage Models Know? (Jiang et al., TACL 2020)